As humans, we understand events in the visual world contextually, performing multimodal reasoning across time to make inferences about the past, present, and future. We introduce MERLOT, a model that learns multimodal script knowledge by watching 6 million YouTube videos with transcribed speech -- in an entirely label-free, self-supervised manner. By pretraining with a mix of both frame-level (spatial) and video-level (temporal) objectives, our model not only learns to match images to temporally corresponding words, but also to contextualize what is happening globally over time.
MERLOT exhibits strong out-of-the-box representations of temporal commonsense, and achieves state-of-the-art performance on 12 different video QA datasets when finetuned. It also transfers well to the world of static images, allowing models to reason about the dynamic context behind visual scenes. On Visual Commonsense Reasoning, MERLOT answers questions correctly with 80.6% accuracy, outperforming state-of-the-art models of similar size by over 3%, even those that make heavy use of auxiliary supervised data (like object bounding boxes).

Paper

@inproceedings{zellersluhessel2021merlot,
title={MERLOT: Multimodal Neural Script Knowledge Models},
author={Zellers, Rowan and Lu, Ximing and Hessel, Jack and Yu, Youngjae and Park, Jae Sung and Cao, Jize and Farhadi, Ali and Choi, Yejin},
booktitle={Advances in Neural Information Processing Systems 34},
year={2021}
}
Model and Objectives
MERLOT has two modules. An Image Encoder (a ResNet50 followed by a base-sized Vision Transformer) encodes each video frame. We fuse language and vision together, and across time, using a Joint Encoder (another base-sized Transformer).
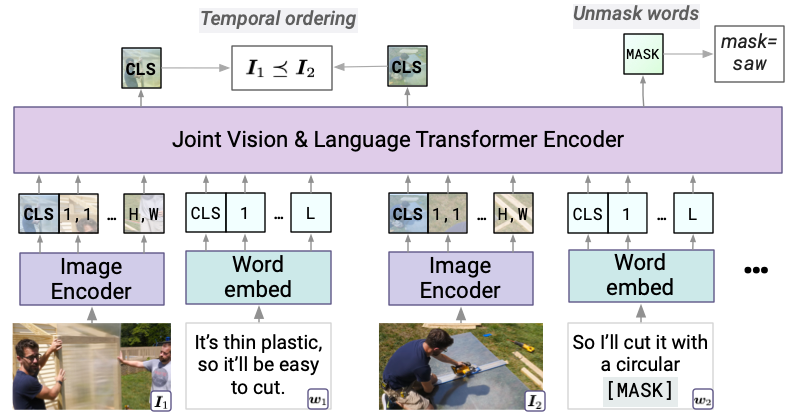
The architecture also handles image-based tasks, like VCR, as a special case. We train the joint encoder using two objectives: correctly ordering (possibly shuffled) image frames, and predicting the identity of MASKed tokens.
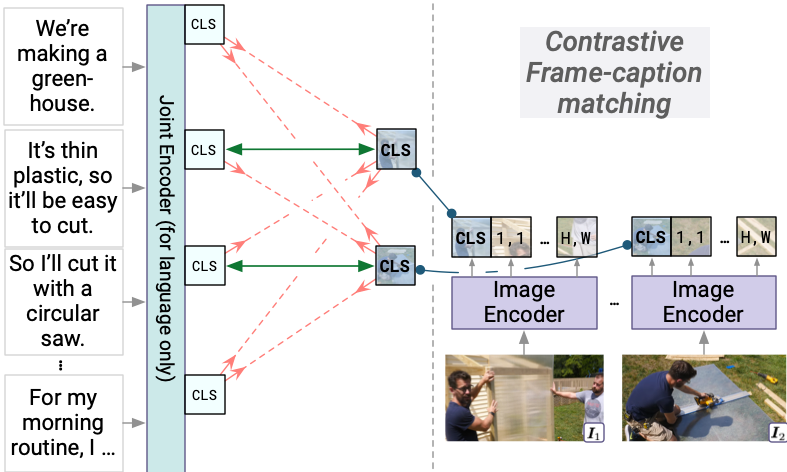
Our model uses no human supervision (like object detections or captions). Instead, we learn recognition-level visual knowledge through a contrastive objective. The model contrastively matches encoded image representations to a contextualized representation of the transcript.
Results
When finetuned, MERLOT does well across a variety of language and vision tasks, including state-of-the-art base-sized results on Visual Commonsense Reasoning, TVQA (lux32), and VLEP (lux32).
We test MERLOT's innate multimodal script knowledge by having it unscramble visual stories. A story about 5 images is given to the model, and it has to correctly order the (shuffled) images. It does this with a pairwise accuracy of 84.5%, outperforming independent image-text matching models.
Examples
Use the dropdown menu to look at stories ordered by the model. Note: these stories (from the SIND dataset) were written by Mechanical Turk workers who were given image. A few of the descriptions are somewhat problematic; we (the authors) do not endorse these.
Dataset
We trained MERLOT on YT-Temporal-180M, a large and diverse dataset of 6 million videos (spanning 180M extracted frames) that covers diverse topics. We found that both topic diversity (e.g. not just How-To videos) and dataset size improved MERLOT's performance.
To enable reproducibility while also protecting user privacy, we've publicly released the video metadata (including the titles and YouTube IDs of the videos), but not the videos themselves. The annotations are released as 100 gzipped jsonl files in the following Google cloud storage bucket:
gs://merlot/yttemporal180m/yttemporal180m_{i:03d}of100.jsonl.gz
for i in range(100). We also have code available for processing data, among other utilities.
Authors
This was a collaborative work between researchers at the University of Washington and the Allen Institute for AI (AI2). 🍷: Equal first author contribution.








Contact
Questions about neural script knowledge, or want to get in touch? Contact Rowan at rowanzellers.com/contact.


