CVPR 2022 Notes
July 04, 2022A week ago, I attended CVPR 2022 in New Orleans. It was super fun seeing everyone in person, and I figured I'd share some reflections on the conference.
Overall takeaways
At the conference, I presented MERLOT Reserve, which went well. The conference wasn't as busy as past CVPRs due to COVID, but our poster session still felt busy!

CVPR 2022 felt different from past CVPRs in other ways, too. Many papers make use CLIP in either a finetuned or zero-shot setting. In the last two in-person CVPRs in 2018 and 2019, there instead was a lot of focus on designing better CNN architectures, and better pipelined object detectors. Most of these models were trained from scratch.
What's next? There's a lot of interest in embodied vision -- even a panel on it. One panelist remarked that (paraphrased): as soon as computer vision tries to engage with the real world, things break and it's too hard, so people give up. I feel like this has lots of similarities with other areas (e.g. commonsense in language used to be "too hard").
What's the solution here? I've noticed that robotics people are in favor of imposing structure, symbols, and/or planning. On the other hand, the communities of vision/language/ML tend to support making everything end-to-end.
I believe in a synthesis between these two views, but I think it'll be a lot closer to the end-to-end side. I'm skeptical about explicit structure and symbolic planning. At the same time, I think we might need new solutions to known problems (e.g. dealing with biased, open-ended, and non-stationary environments without catastrophic forgetting). Maybe those solutions will just look like more web pretraining, or maybe they'll blur the lines between what we now consider pretraining, finetuning, and testing.
Another interesting insight from the panel: perhaps we indeed need some elements from logical manipulation. Not logic architecture necessarily, but being able to generalize and compose things together that are syntatically valid without destroying semantics. It's not obvious whether today's strongest pretrained models can truly do this. Though, for instance, image generators today seem pretty good at mashing together various concepts specified in natural language!

Specific papers
I thought I'd provide some half-baked thoughts on a few papers from the conference:
Atemporal Probing (Shyamal Buch et al)
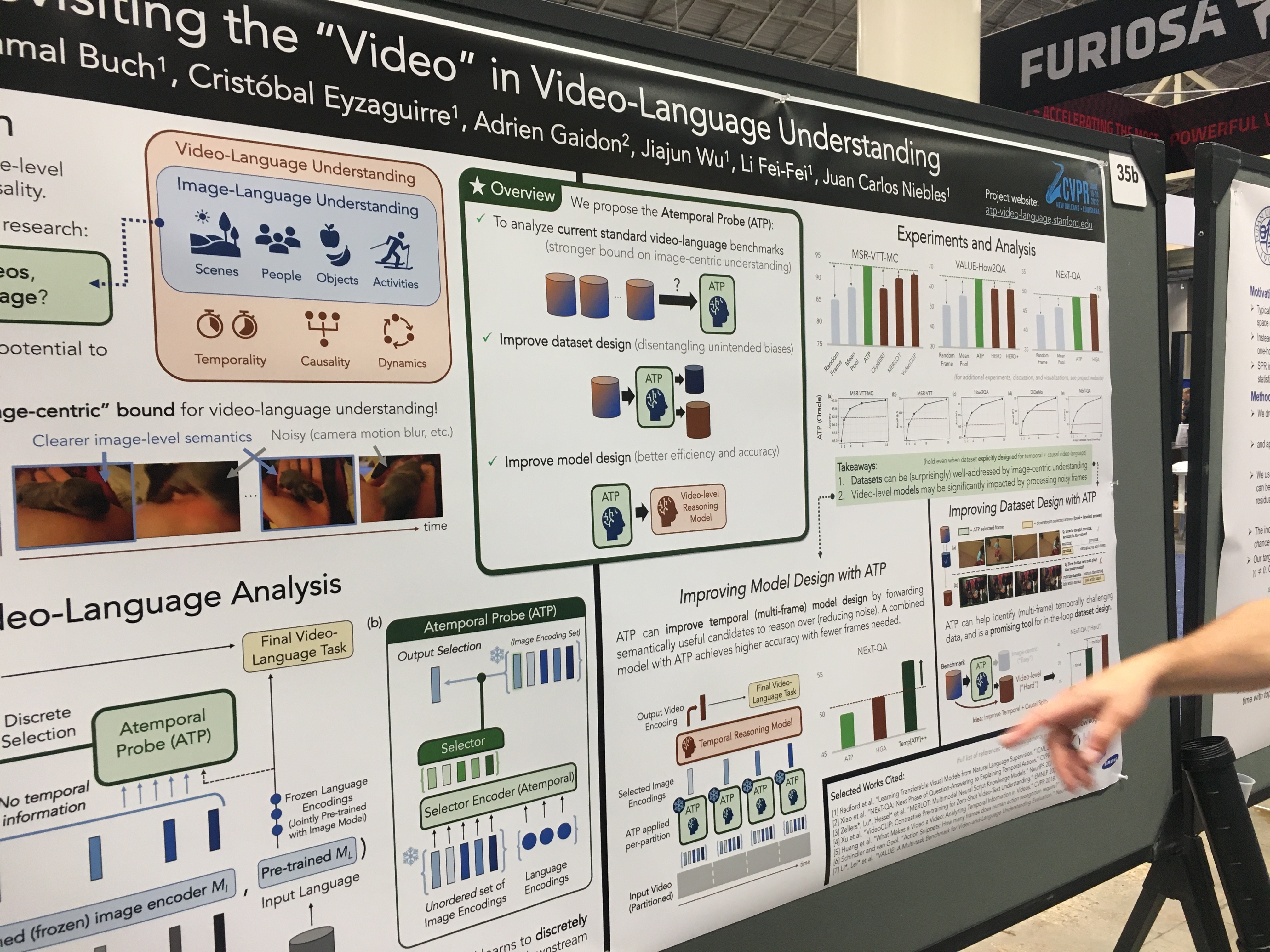
Summary: Many video benchmarks are gameable by picking out a few frames in isolation (e.g. if we see a basketball court, likely people will be playing basketball). This creates problems when we use these benchmarks to evaluate video understanding.
This paper proposes a simple baseline for multiple-choice video tasks that intentionally doesn't model temporality. A frozen CLIP model embeds each frame in a video, a frozen CLIP model embeds a question, and a transformer model is finetuned over 1. an unordered set of video embeddings, and 2. the language, to select the best frame. The best frame is used to answer the question (e.g. with a finetuned video QA head).
Thoughts: Building benchmarks is challenging, especially for something as complex as video. The recognition-based baseline proposed here does quite well, even outperforming MERLOT V1 on MSR-VTT video QA. There could be a bunch of reasons this might be the case, and all of them are pretty interesting, though:
- Selecting all frames helps us find a clear, and non-blurry, shot that captures everything we'd need in order to answer the question. On the other hand, methods like MERLOT or ClipBERT sample one frame every few seconds. This either drops out key events, or leads to us sampling key events but with a blurry frame.
- Finetuning on a small dataset leads to weird dynamics. Possibly, freezing a recognition-based model is the right inductive bias here.
- There might be something special and learnable with the set-based video encoding. Even if the elements to the set are provided 'unordered', at a high framerate models might be able to reconstruct the order, and use a weak notion of temporality to select the right answer.
I don't know what the right answer is here (though the paper might have clues) -- it's clear to me though we need better video benchmarks and models, though!
Richer supervision through event frames (Manling Li et al)
Summary: What's the best way of turning text into supervision for image recognition models? The CLIP approach, where models learn to compress text into a single vector, is the current dominant paradigm -- but it might end up throwing away extra useful supervision (that maybe 'can't be crammed into a single vector').
This paper finetunes CLIP models on news data. The CLIP models must predict event structures that are auto-extracted from the text (using a pretrained parser). The recognition models even exhibit some zero-shot transfer to challenging tasks like imsitu and VCR.
Thoughts: I like the idea of using other structured data to train vision-and-language models. My suspicion is that left-to-right prediction of raw text doesn't seem to be the most efficient approach because the most important concepts aren't said first, so it's harder for models to learn image-text interactions through backprop. Training over parses might address this problem by being simpler as well as being verb-centric -- the limitation is that you really need to trust your semantic/event parser.
CLIP with Progressive Self-Distillation (Alex Andonian et al)
Summary: The idea here is that CLIP is training models to say "1" for matched images but "0" for unmatched, and this isn't what we want from the final model (there's some level of inherent noise). However, it isn't obvious how to find those softer labels. This paper proposes a "self-distillation" approach, which involves using the same model as both the teacher and the student. The teacher gets to see the whole batch to make soft targets, and the student has to logistic-regress to them. During training, the batch-partitioning approach is annealed to give less data to the teacher and more data to the student, as the teacher gets better.
Thoughts: I've never encountered self-distillation before, though it might not be the first one, and there are other ideas floating around (e.g. cross view training). The authors here show that performance increases over a re-implemented CLIP model as data size increases from 1M->12M, which is interesting (many papers show the opposite or don't report such scaling). But I'm not sure whether such trend would continue in the infinite data limit.
TubeDETR: Spatial-Temporal Video Grounding with Transformers (Antoine Yang et al)
Summary: An approach for localizing objects in videos (that might move around) given a text query. Challenges include that videos are long, and it's difficult to get supervision and specify the output space for this task. The model proposed includes both a "slow branch" (with patches from images sampled at 1FPS) and a "fast branch" with coarser features at 5fps. It combines both and does some extra text-language similarity on the slow side. The loss involves extensions to the DETR style matching loss, to handle predictions across the video. Everything is finetuned/evaluated on supervised data like VidSTG.
Thoughts: I feel like we're in the beginning of video understanding and retrieval. The average length here is 1 second long and already there's already a lot that needs to be done in terms of the losses, architecture, etc. I wonder to what extent we can push the DETR paradigm towards longer videos, or whether object detection will even last as an intermediate task.
Computer Vision for Trash Object Segmentation (Dina Bashkirova et al)

Summary: When cities don't make people sort their recyclables (into e.g. paper, glass, metal), recycling centers have to sort them. It would be useful if we could train machines to automatically sort these. An intermediate problem is learning to segment these objects -- this is already a hard task as recycling/trash objects are highly deformable, unlike the 'clean' objects in COCO. The paper proposes a dataset and task for this, and uses it to benchmark segmentation models.
Thoughts: I've never heard of this task before, but I really like it. I think it exposes a limitation of the "clean" images we find in datasets like COCO or on annotated web images more generally. It'll be curious to see what supervision approachs work well in this space.
A very large dataset for egocentric video: Ego4D
Summary: I'd heard about Ego4D before the conference, but it definitely made a splash during the conference too. It's a mega-collaboration between a bunch of different institutions, with hours of recorded egocentric video. The 'boring' and unedited nature of these videos makes them challenging. The paper also extensively annotates the videos, and proposes a suite of new benchmarks on top of them.
Thoughts: I feel like it's an interesting time to make a new large annotated dataset. In NLP at least, large training sets have felt dated to me for a while now, a trend accelerated by GPT3. Many of the big labs end up throwing away (most of) those training sets anyways and doing everything in a few shot setting. That said, maybe releasing training sets and encouraging finetuning might enable broader participation from smaller groups. This could be especially important as operating on long videos can pretty computationally daunting.
Summary
CVPR 2022 was fun, and hope this summary was thought provoking! Do check out the papers I linked and tweet at me if I got any of the details wrong, or if you disagree with my takeaways.