SWAG: A Large-Scale Adversarial Dataset for Grounded Commonsense Inference (EMNLP 2018)
Read the paper » Get the code » Download the data » View or submit to the leaderboard » EMNLP 2018 talk slides»For an even harder dataset, check out HellaSwag (ACL 2019):
HellaSwag »
About the Dataset
Given a partial description like "she opened the hood of the car," humans can reason about the situation and anticipate what might come next ("then, she examined the engine"). SWAG (Situations With Adversarial Generations) is a large-scale dataset for this task of grounded commonsense inference, unifying natural language inference and physically grounded reasoning.
The dataset consists of 113k multiple choice questions about grounded situations. Each question is a video caption from LSMDC or ActivityNet Captions, with four answer choices about what might happen next in the scene. The correct answer is the (real) video caption for the next event in the video; the three incorrect answers are adversarially generated and human verified, so as to fool machines but not humans. We aim for SWAG to be a benchmark for evaluating grounded commonsense NLI and for learning representations.
Try some interactive examples below!
We notice a man in a kayak and a yellow helmet coming in from the left. As he approaches, his kayak...
The person blows the leaves from a grass area using the blower. The blower...
Staying under, someone swims past a shark as he makes his way beyond the lifeboat. Turning, he...
Download SWAG
SWAG is distributed as a CSV file. We have data for the training (73k questions) and validation (20k questions) splits available online. The test split (20k questions) is blind for evaluation. Check out the leaderboard to submit.
Adversarial Filtering
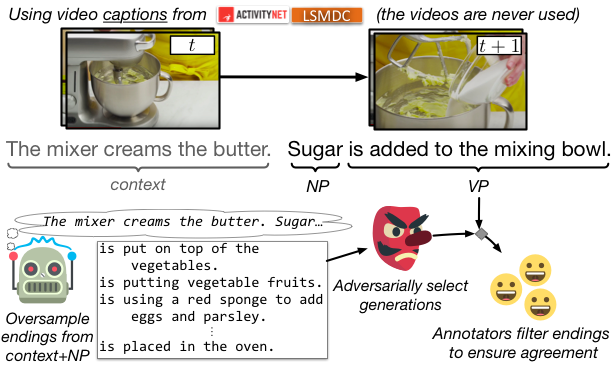
To address the recurring challenges of the annotation artifacts and human biases found in many existing datasets, our paper introduces Adversarial Filtering, a novel procedure that constructs a minimally-biased dataset by iteratively training an ensemble of stylistic classifiers, and using them to filter the data. We build SWAG with this methodology: we used language models to massively oversample the counterfactual answers, and stylistic models to filter them. This results in a dataset that is large-scale yet robust against simple stylistic baselines.
To help other researchers use Adversarial Filtering to create similarly robust benchmarks, we've released the code on Github.
Paper

@inproceedings{zellers2018swagaf,
title={SWAG: A Large-Scale Adversarial Dataset for Grounded Commonsense Inference},
author={Zellers, Rowan and Bisk, Yonatan and Schwartz, Roy and Choi, Yejin},
booktitle = "Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
year={2018}
}




Contact
Questions about the dataset, or want to get in touch? Contact Rowan Zellers at my contact page, open up a pull request on Github.