MERLOT Reserve: Multimodal Neural Script Knowledge through Vision and Language and Sound (CVPR 2022)
Paper » Demo » Code »As humans, we navigate the world through all our senses. We introduce MERLOT Reserve, a model that learns to represent videos over time and across modalities: audio, subtitles, and video frames. We train it through a new learning objective, over 20 million YouTube videos.
Empirical results show that our model learns strong representations about videos, through all constituent modalities. When finetuned, it sets a new state-of-the-art on both VCR and TVQA, outperforming prior work by 5% and 7% respectively. We show that both tasks benefit from audio pretraining, even VCR (which is centered around images, without provided sound).
Our learning objective also enables transfer to zero-shot tasks. It obtains competitive results on four video understanding tasks, even outperforming supervised approaches on the recently-proposed Situated Reasoning (STAR) benchmark. Our paper has more analysis and discussion about these results and their implications.

Paper

@inproceedings{zellers2022merlotreserve,
title={MERLOT Reserve: Multimodal Neural Script Knowledge through Vision and Language and Sound},
author={Zellers, Rowan and Lu, Jiasen and Lu, Ximing and Yu, Youngjae and Zhao, Yanpeng and Salehi, Mohammadreza and Kusupati, Aditya and Hessel, Jack and Farhadi, Ali and Choi, Yejin},
booktitle={CVPR},
year={2022}
}
Model and Objectives
We build on our previous work MERLOT (Zellers, Lu, Hessel et al; NeurIPS 2021), which learns Multimodal Neural Script Knowledge from video frames and subtitles. In this work, we aim to learn how to fuse audio alongside video and subtitles, and to do so with supervision from subtitles and audio.
MERLOT Reserve processes a video by first encoding each modality independently, then jointly. A Vision Transformer encodes each video frame. We process language by either using an Audio Spectrogram transformer to encode audio, or a word embedding table to encode subtitles. We use a Joint Transformer Encoder to fuse all modalities together and across time.
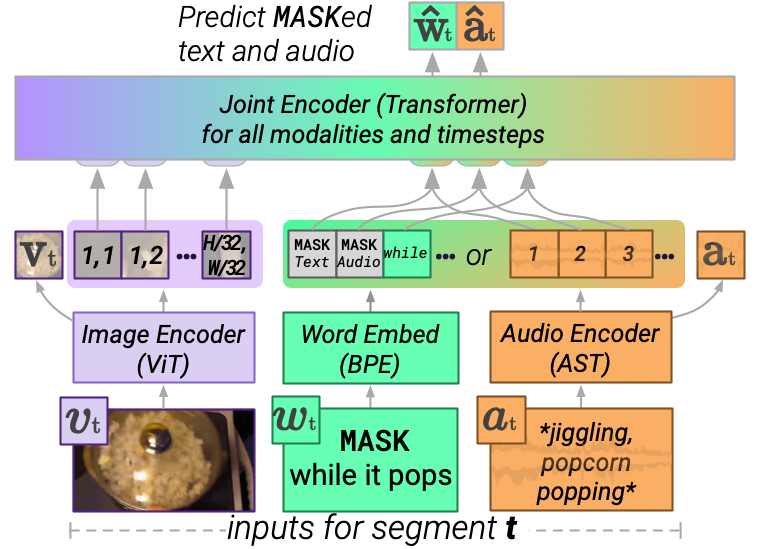
The architecture allows us to simultaneously handle video tasks (with either subtitles, or audio), and image-based tasks like VCR. We train the model through a new contrastive objective. Given a video with its frames, text, and audio temporally aligned, we MASK out a region. The model must maximize the similarity of the MASKed region to an independent encoding of that region's text and audio.
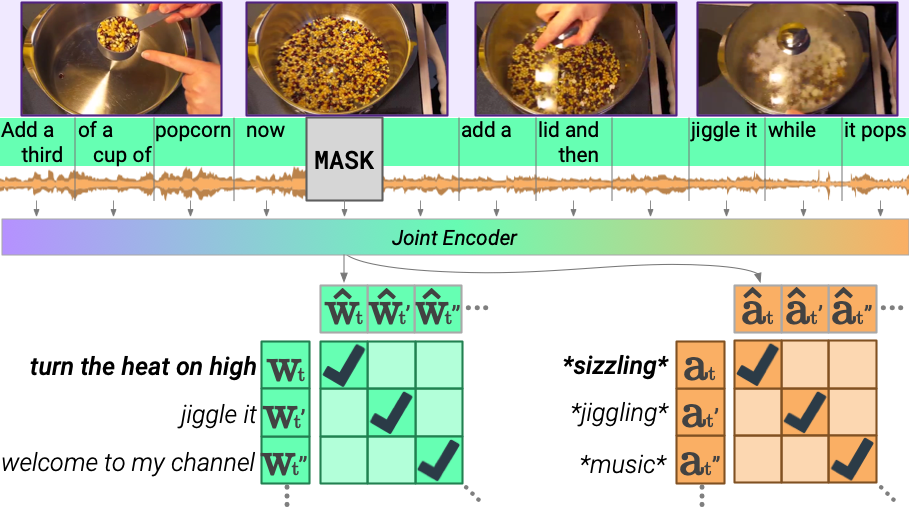
The new objective thus enables learning to fuse audio as well as learning from audio.
Results
When finetuned, MERLOT Reserve gets state-of-the-art results for its size on VCR and TVQA. The results on TVQA show additional performance gain when audio is used -- which no past work has been able to capture.
Beyond SOTA finetuning performance, our model can be used for a variety of zero-shot video understanding tasks. A question like "What is the person doing?" can be rewrittten into a statement like "The person is MASK." The model will then do multiple-choice prediction over a set of provided options (e.g. "cooking popcorn", "eating popcorn"). The rewriting can be done manually, or automatically via a language model.
Demo »Dataset
We trained MERLOT Reserve on YT-Temporal-1B. With MERLOT, we previously found success on training on videos at scale, from different topics -- including documentaries, how-to videos, and vlogs. To make the dataset size comparable to similar efforts in the image-only space (like JFT-3B), we collected a dataset of 20 million videos for this work, spanning over a billion frames.
To enable reproducibility while also protecting user privacy, we've publicly released the video IDs and information. The video IDs are here:
gs://merlot/yttemporal1b/yttemporal1b_ids_train.csv gs://merlot/yttemporal1b/yttemporal1b_ids_val.csv
We have video metadata (including the title and description) as well:
training: f'gs://merlot/yttemporal1b/train_annotations/yttemporal1b_train_{i:04d}of1024.jsonl.gz' for folds i between 0 and 1023.
validation: gs://merlot/yttemporal1b/yttemporal1b_val_0000of0001.jsonl.gz
At our Github repository, we have various utilities for preprocessing the data (which help avoid spurious correlations during model pretraining).
Authors
This was a collaborative work between researchers at the University of Washington and the Allen Institute for AI (AI2).










Contact
Questions about neural script knowledge, or want to get in touch? Contact Rowan at rowanzellers.com/contact.


